New
We've just released questions for AWS AI Practitioner AIF-C01
Intelligent practice exams
for AWS certifications
Our practice exams focus on knowledge gaps, and don't waste time on what you already know.
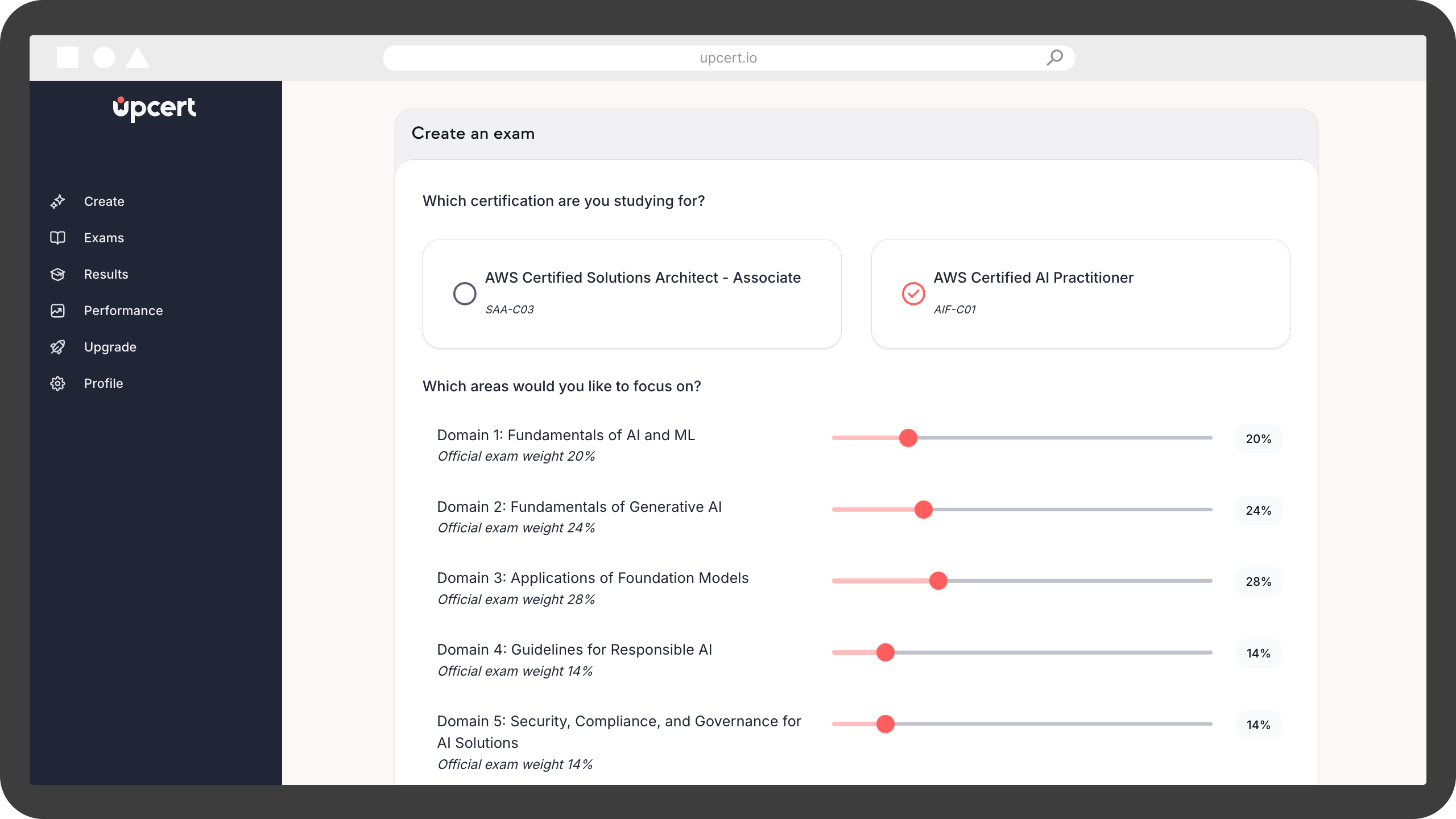


Create Custom Practice Exams
Select the exact topics and domains you want to focus on.
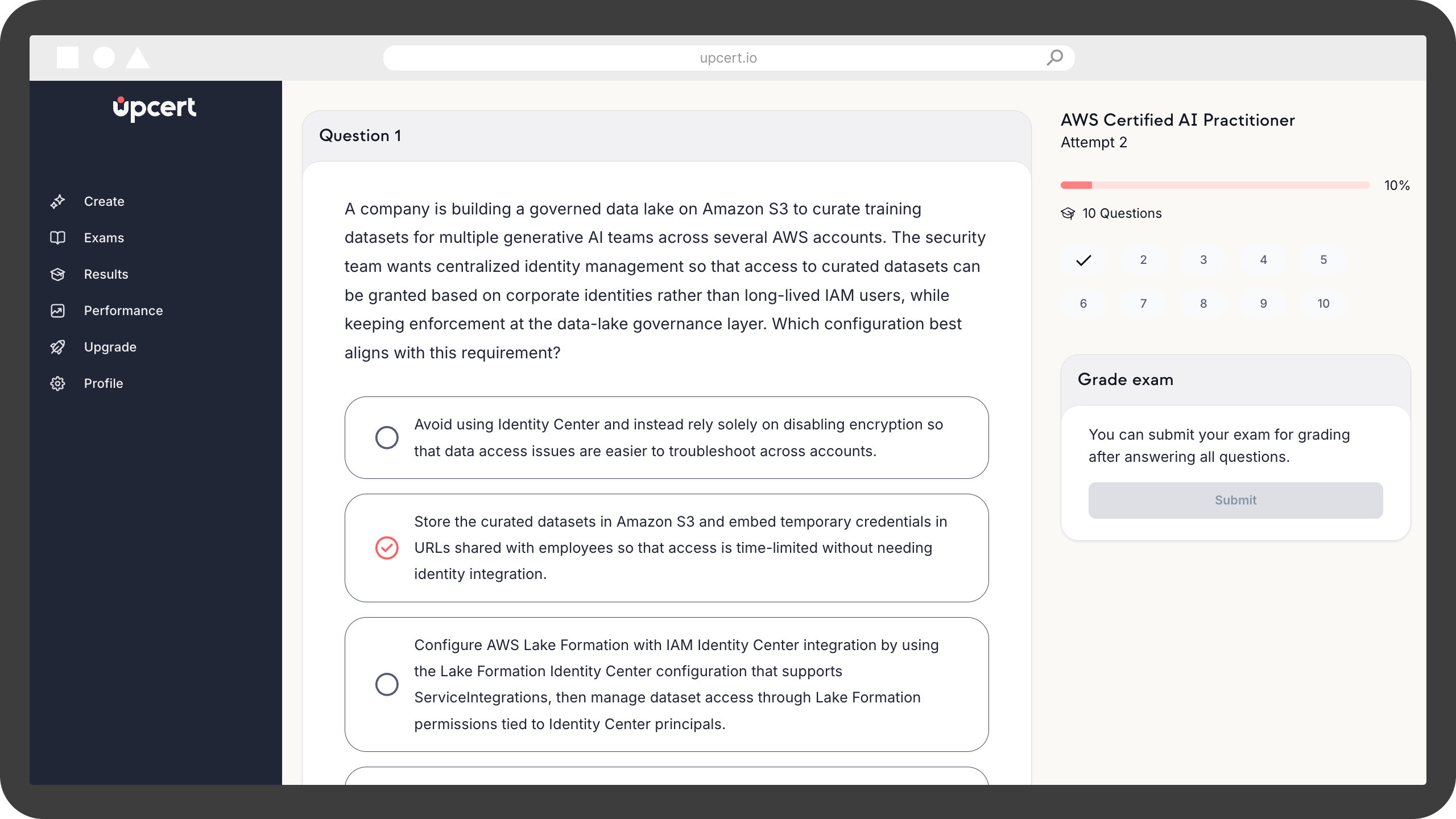
Instant Feedback & Detailed Explanations
Understand both correct and incorrect answers with clear explanations.

Official Documentation Links
Reinforce your learning with direct links to the relevant documentation.

Focus on Your Weak Areas
Automatically generate exams based on the topics you need to improve.

Know When You’re Exam-Ready
Get notified when your results indicate you’re ready to sit the exam.

Practice exams
AWS
AI Practitioner (AIF-C01)
Validate foundational knowledge of artificial intelligence, machine learning concepts, and how AWS AI/ML services are used to build practical, real-world solutions.
AWS
Solutions Architect - Associate (SAA-C03)
Foundational knowledge of designing secure, resilient, and cost-efficient architectures using AWS services.
AWS
Cloud Practitioner (CLF-C02)
The AWS Certified Cloud Practitioner validates foundational, high-level understanding of AWS Cloud, services, and terminology.
AWS
Developer – Associate (DVA-C02)
AWS Certified Developer - Associate showcases skills and knowledge in developing, optimizing, packaging, and deploying applications, using CI/CD workflows, and identifying and resolving application issues.

Still have questions?
I’m Jamie, the creator behind Upcert. If you have any questions or feedback, feel free to reach out to me directly on X.